Functional DDCR API — Real Passband to Baseband¶
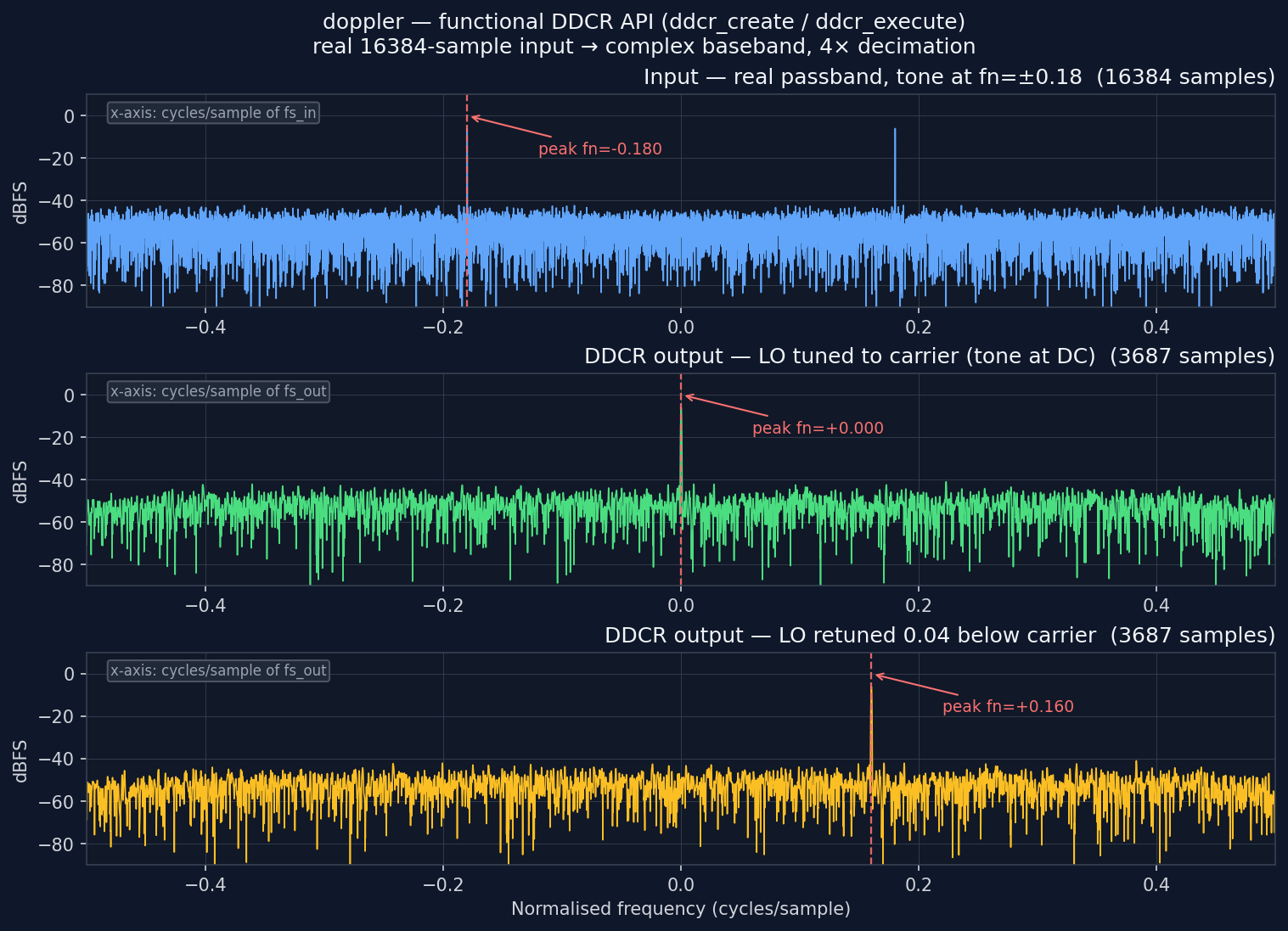
What you're seeing¶
Three panels share the same x-axis — normalised frequency in cycles/sample (−0.5 to +0.5). A red dashed marker labels the strongest spectral line in each panel.
Top panel — input. 16384 samples of a real float32 signal: a tone at
fn = 0.18 (relative to the input sample rate fs_in) plus broadband noise.
Because the input is real, the spectrum is symmetric — the tone shows at both
±0.18.
Middle panel — baseband output. The same signal run through ddcr_execute
with the NCO tuned so the carrier lands at DC. The output is complex64
and decimated 4× (rate = 0.25), so its x-axis is normalised to fs_out. The
tone sits at fn = 0.000.
Bottom panel — retuned output. The LO is moved 0.04 (in fs_in) below the
carrier via ddcr_set_norm_freq. The tone shifts off DC by
0.04 / rate = 0.16 in fs_out units, landing at fn = +0.160 — exactly as
predicted, and phase-continuously (no filter-history reset).
The two faces of the DDC¶
doppler.ddc exposes the same C down-converter two ways:
| Object API | Functional API (this demo) | |
|---|---|---|
| Import | from doppler.ddc import DDCR |
from doppler.ddc import ddcr_create, … |
| State | wrapped in a Python type | opaque PyCapsule, passed explicitly |
| Output | allocated per call | written into a caller-owned buffer |
| Use when | you want a simple object | you manage your own arrays / want zero |
| per-call allocation in a hot loop |
How it works¶
A DDCR takes a real passband signal, mixes it with a fine NCO (running at
fs_in / 2), low-pass filters, and decimates to complex baseband. To park
a real tone at carrier f_carrier (normalised to fs_in) at DC:
The functional lifecycle is explicit — the capsule is yours to keep, reuse, and release:
import numpy as np
from doppler.ddc import (
ddcr_create, ddcr_execute, ddcr_set_norm_freq,
ddcr_reset, ddcr_destroy,
)
state = ddcr_create(norm_freq=-(2 * 0.18 + 0.5), rate=0.25)
out = np.empty(4096, dtype=np.complex64) # reused every block
for block in stream: # block: ndarray[float32]
y = ddcr_execute(state, block, out) # zero-copy view out[:n_out]
...
ddcr_set_norm_freq(state, -(2 * 0.14 + 0.5)) # retune, phase-continuous
ddcr_reset(state) # zero all history
ddcr_destroy(state) # release C resources
After ddcr_destroy, any further call on the same capsule raises
RuntimeError; live views of earlier output stay valid because they reference
the caller's buffer, not the state.
Streaming semantics — the capsule is mutable C state¶
state is an opaque handle — a PyCapsule wrapping a single C pointer — to a
struct that is mutated in place on every call. The actual DDCR state (the
LO phase, the halfband taps, the polyphase resampler banks, the history
buffers) lives entirely in C and never crosses the Python/C boundary: each
call passes the ~8-byte handle, not the kilobytes of state, so nothing is
serialized, marshaled, or copied per call. That is also what makes block-by-block
processing phase-continuous — the same capsule carries its history forward
from one ddcr_execute to the next, so feeding a signal as two halves through
the same state is bit-identical to processing it in one shot:
# one shot ----------------------------------------------------------------
s = ddcr_create(lo, 0.25)
y_whole = ddcr_execute(s, x, out).copy()
# same input, same state, two blocks --------------------------------------
s = ddcr_create(lo, 0.25)
y0 = ddcr_execute(s, x[:4096], out).copy() # state advances in place
y1 = ddcr_execute(s, x[4096:], out).copy() # picks up exactly where y0 left off
# np.concatenate([y0, y1]) == y_whole (max|Δ| == 0)
Run those same two halves through fresh states instead and the seam shows a
phase jump and a filter transient (max|Δ| ≈ 0.78) — the carried history is
exactly the in-place state. ddcr_set_norm_freq and ddcr_reset likewise
mutate the same capsule (no new handle is returned).
Consequences:
- One capsule = one stream. Don't share a capsule across threads concurrently; give each stream its own.
- Deterministic lifetime.
ddcr_destroyfrees the C resources when you say so, not when the GC happens to run. - The only value handed back is the output view (
out[:n_out]); everything else lives in — and mutates — the capsule.
Performance — zero-copy, zero steady-state allocation¶
The functional face is not faster than the DDCR object — it's the same C
core, and on a 4096-sample block all three paths land within ~2 %
(≈16 µs/block on this machine). The benefit is where the output goes and
what gets allocated, not raw throughput:
| Path | per-call allocation | output lands in |
|---|---|---|
ddcr_execute(state, x, out), out reused |
none (steady state) | a buffer you own |
ddcr_execute(state, x, np.empty(...)) |
one output array | a fresh array each call |
DDCR.execute(x) (object) |
none | one internal buffer, overwritten next call |
So the functional API buys you:
- Zero-copy into caller memory. Write results straight into a slice of a larger array, a memory-mapped region, or the next pipeline stage's input buffer — no copy to move the result into place afterward.
- Multiple live outputs. The object's
executereturns a view into one internal buffer that the next call overwrites; the functional API can target a differentoutper call, so several outputs stay valid at once. - No per-call allocation in the steady state when you reuse one
out— small here (the allocator recycles the 32 KiB block cheaply), but it removes allocator traffic and GC pressure entirely, which matters under many parallel streams or tight real-time budgets.
Parallelism — ddcr_execute releases the GIL¶
The C kernel runs with the GIL released (Py_BEGIN_ALLOW_THREADS around the
ddcr_execute call). It's safe precisely because of the one-capsule-per-stream
contract: the kernel touches only that stream's state and the caller's
buffers — no Python objects, no shared mutable state. So a thread-per-shard
worker — each thread owning its own capsule and out buffer — scales across
cores instead of serialising on the GIL:
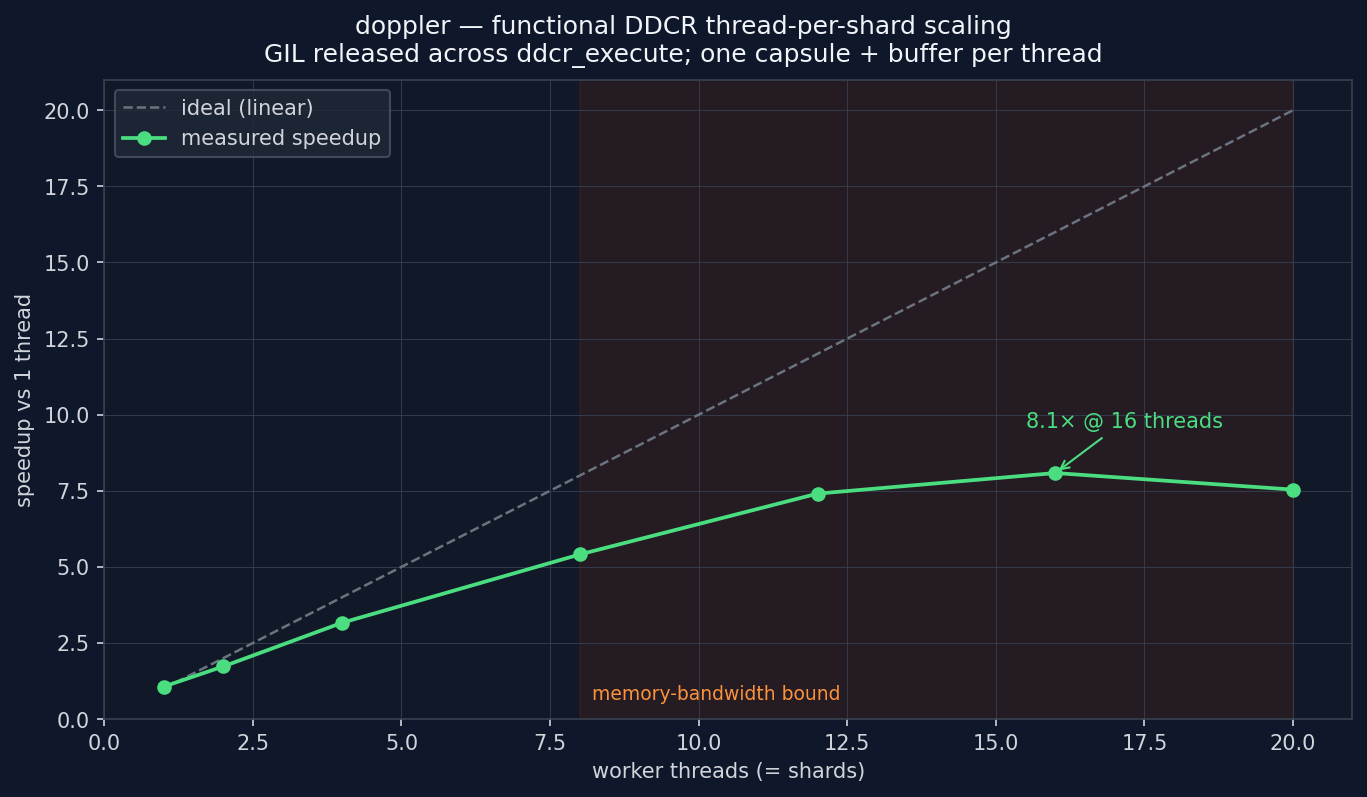
| threads | speedup | efficiency |
|---|---|---|
| 1 | 1.00× | 100 % |
| 2 | 1.73× | 86 % |
| 4 | 3.16× | 79 % |
| 8 | 5.41× | 68 % |
| 12 | 7.41× | 62 % |
| 16 | 8.08× | 51 % |
(8192-sample blocks, representative run on a 20-core box; regenerate with
make gallery. Before releasing the GIL the same test was flat at ~1×
regardless of thread count.) Scaling is near-linear through a handful of cores
and then memory-bandwidth bound — the kernel streams large buffers, so past
~8–12 threads more cores stop helping. The takeaway for sizing: one replica can
use several cores via threads before you reach for process-per-shard, which
changes your replica-count math.
This pairs directly with the streaming model above: shard by stream, give each worker thread a disjoint set of capsules, and there is no shared state to lock — the parallelism is embarrassingly so.
In short: same speed, but you own the buffer and the lifetime — exactly what a zero-copy streaming pipeline wants.
Run it¶
Source: examples/python/ddc_fn_demo.py