Composing a Scene — .sum(), .add(), and Headroom¶
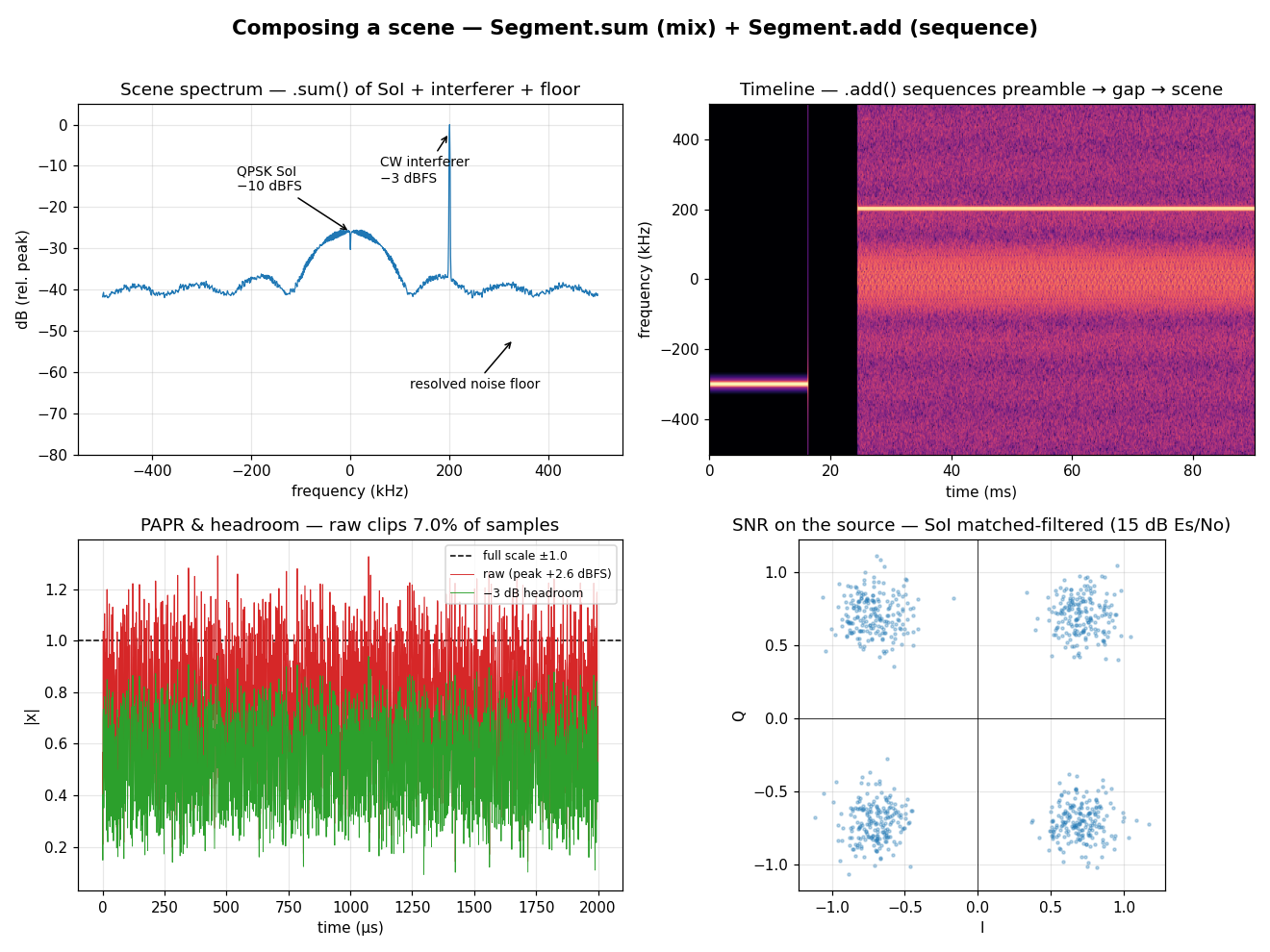
A realistic capture is rarely one waveform. It is a scene: a signal of interest, some interferers, and a noise floor — possibly changing over time. The waveform composer builds exactly that from two orthogonal verbs, with the amplitude bookkeeping done for you.
Segment.sum(*sources)mixes sources at the same time (one receiver → one sample rate, one shared noise floor).Segment.add(*segments)sequences segments in time, back-to-back.
Everything below is the Python API; the wfmgen CLI (--from-file a JSON
spec) and a recorded run (--record) produce byte-identical samples,
because the amplitude and noise resolution all happen once, in C.
What you're seeing¶
Top-left — the scene's spectrum. Segment.sum mixes a −10 dBFS QPSK signal
of interest at baseband with a −3 dBFS CW interferer at +200 kHz. SNR lives on
the SoI (snr=15, Es/No); the composer resolves that into one explicit AWGN
floor in C. So in the raw spectrum the SoI sits its over-fs SNR above the
floor — the full 15 dB Es/No is realised later, by the receiver's matched filter
(bottom-right). One .sum() call, three power levels, one floor.
Top-right — the timeline. Segment.add sequences a clean preamble tone
burst (at −300 kHz), a short gap, then the scene. The spectrogram shows the
hand-off in time — the composer simply plays its segment list back-to-back.
Bottom-left — PAPR and headroom. A sum of two tones plus noise is not
constant-envelope, so its peak runs past full-scale: here the raw composite
peaks at +2.6 dBFS and an integer capture clips 7 % of its samples (red).
headroom backs the whole composite off by 3 dB so the peak fits under ±1.0
(green). Headroom is a single scale, so it moves the absolute level without
touching any power ratio — the SNR is unchanged.
Bottom-right — SNR on the source. The SoI in isolation, matched-filtered:
the four Gray-coded QPSK points and their cloud are the snr=15 Es/No made
visible. Because SNR is a property of the source (its snr_mode needs the
source's bits/symbol and samples/symbol), this is the very number the scene's
shared floor was resolved from.
Building it¶
import numpy as np
from doppler.wfm import Composer, Segment, Writer, qpsk, tone
# 1. Mix a scene: a QPSK SoI under a CW interferer, over one noise floor.
soi = qpsk(snr=15, snr_mode="esno", sps=8, level=-10.0, seed=1)
inter = tone(freq=2e5, level=-3.0) # −3 dBFS CW at +200 kHz
scene = Segment.sum(soi, inter, num_samples=1 << 16) # the floor is resolved in C
# 2. Sequence it after a preamble (time, not frequency).
preamble = Segment("tone", freq=-3e5, num_samples=16384, off_samples=8192)
timeline = preamble.add(scene)
x = Composer(timeline).compose() # → complex64
The snr on the SoI is all you specify; Segment.sum resolves the anchor
(the first source carrying snr), places the floor at
level(anchor) − SNR_fs(anchor), and appends an explicit noise source there.
Interferers set their power with level; an explicit noise(level=…) source pins
the floor directly. (Giving a non-anchor both snr and level is a spec
error — pick one.)
Headroom and clip detection¶
The composite has PAPR, so integer captures can clip. The Writer always tracks
the running peak (free), and headroom backs the output off so it fits:
with Writer("scene.cf32", sample_type="ci16", headroom=3.0) as w:
w.write(x)
print(f"peak {w.peak_dbfs:+.1f} dBFS, clipped: {w.clipped}")
# Or detect first, then dial in exactly enough headroom:
with Writer("probe.ci16", sample_type="ci16") as w:
w.track_clipping()
w.write(x)
need = max(0.0, np.ceil(w.peak_dbfs)) # dB to fit under full scale
headroom is SNR-invariant — it scales every source together, so the scene's
relative levels (and the recovered Es/No) are untouched; it only moves the
absolute level under full-scale.
Reproducible to the sample¶
The fully-resolved scene — cleaned anchor, explicit noise floor, and the headroom — round-trips through JSON, so a capture is reproducible anywhere:
spec = Composer(timeline).to_json() # the resolved "sum" spec
assert np.array_equal(Composer.from_json(spec).compose(), x)
# the same, from the CLI — a.cf32 and b.cf32 are byte-identical
wfmgen --from-file scene.json --headroom 3 --record run.json -o a.cf32
wfmgen --from-file run.json -o b.cf32
See also¶
- Waveform Generator guide — the full flag/parameter reference, containers (BLUE/SigMF), and the mixing/sequencing section.
- Waveform amplitude & composition — the design rationale (average-power amplitude, PAPR, the noise-floor model).
examples/python/wfm_composition_demo.py— the script behind this figure.